Машинный перевод
Содержание:
Комментарии
- Впрочем, это не так: Polyglossum (sic) — это электронный словарь, программа того же класса, что и Lingvo, самостоятельно переводить не способная. В то время он существовал в версиях для DOS и Windows 3.x и, уступая Lingvo и Context по качеству общего словаря, имел рекордный объём специализированных словарей. К тому же отдельные ошибки перевода выдают подделку — вероятно, после машинного перевода текст редактировался вручную : «Замечательный пример текста, полученного якобы при помощи медико-биологического словаря в результате перевода руководства по работе с драйверами мыши, называется „Гуртовщики Мыши“ … не верю в чистоту эксперимента: наверняка там не обошлось без поправок, внесенных в текст рукой человека».
Статистический машинный перевод
Статистический машинный перевод — это разновидность машинного перевода текста, основанная на сравнении больших объёмов языковых пар. Языковые пары — тексты, содержащие предложения на одном языке и соответствующие им предложения на втором, могут быть как вариантами написания двух предложений человеком — носителем двух языков, так и набором предложений и их переводов, выполненных человеком. Таким образом статистический машинный перевод обладает свойством «самообучения». Чем больше в распоряжении имеется языковых пар и чем точнее они соответствуют друг другу, тем лучше результат статистического машинного перевода.
Под понятием «статистического машинного перевода» подразумевается общий подход к решению проблемы перевода, который основан на поиске наиболее вероятного перевода предложения с использованием данных, полученных из двуязычной совокупности текстов. В качестве примера двуязычной совокупности текстов можно назвать парламентские отчеты, которые представляют собой протоколы дебатов в парламенте. Двуязычные парламентские отчеты издаются в Канаде, Гонконге и других странах; официальные документы Европейского экономического сообщества издаются на 11 языках; а Организация объединенных наций публикует документы на нескольких языках. Как оказалось, эти материалы представляют собой бесценные ресурсы для статистического машинного перевода.
Качество перевода
Качество перевода зависит от тематики и стиля исходного текста, а также грамматической, синтаксической и лексической родственности языков, между которыми производится перевод. Машинный перевод практически всегда оказывается неудовлетворительного качества. Тем не менее для технических документов при наличии специализированных машинных словарей и некоторой настройке системы на особенности того или иного типа текстов возможно получение перевода приемлемого качества, который нуждается лишь в небольшой редакторской корректировке.[источник не указан 2978 дней] Чем более формализован стиль исходного документа, тем большего качества перевода можно ожидать. Самых лучших результатов при использовании машинного перевода можно достичь для текстов, написанных в техническом (различные описания и руководства) и .
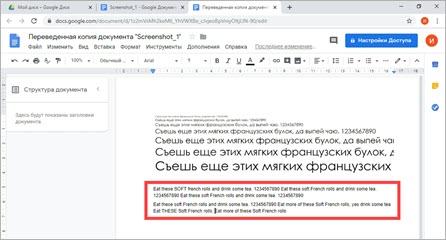
Чаще всего подобные шутки связаны с тем, что программа не распознаёт контекст фразы и переводит термины дословно, к тому же не отличая собственных имён от обычных слов. Тот же переводчик ПРОМТ превращал «Лев Толстой» в «Lion Thick» («толстый лев»), «bra-ket notation» в «примечание Кети лифчика», «Lie algebra» — в «алгебру Лжи», «eccentricity vector» — в «вектор оригинальности», «Shawnee Smith» в «индеец племени шони Смит» и т. п. Переводчик Google, наоборот, слово «rice» часто принимал за фамилию госсекретаря США.
Немного теории
Для того чтобы понять, насколько совершенны или несовершенны современные переводчики,
следует сказать несколько слов об истории формирования подобного рода программ
и коротко ознакомить читателя с самыми общими подходами построения алгоритмов,
применяемых для их создания.
Как формировалась школа машинного перевода
Датой рождения машинного перевода обычно считают конец 40-х годов. Одним из
первых о машинном переводе заговорил Уоррен Вивер, директор отделения естественных
наук Рокфеллеровского фонда, который, обращаясь в письме к Норберту Винеру,
сравнивал задачу перевода с задачей дешифровки текстов: «Глядя на статью на
русском языке, я говорю себе: в действительности статья написана по-английски,
но зашифрована какими-то непонятными знаками», и после этого начинаю ее расшифровывать».
В 1949 году он опубликовал документ, который имел весьма громкое название: «Решение
мировой проблемы перевода». В 1952 году состоялась первая конференция, на которой
обсуждались подходы к созданию систем машинного перевода, а уже в 1954 году
компания IBM разработала первую систему, содержавшую словарь из 250 слов и 6
синтаксических правил и обеспечивавшую перевод заранее отобранных предложений.
Этот эксперимент дал старт интенсивным десятилетним исследованиям, на которые
правительство США истратило почти 40 млн. долл.
Однако в начале 60-х пришлось констатировать, что поставленная задача оказалась
слишком сложной и что системы автоматического перевода не смогут в обозримом
будущем обеспечить приемлемое качество перевода. Большинство программ машинного
перевода увязали в многозначности слов и обилии идиоматических выражений. Начатые
работы не привели к практическим результатам, однако выявили многие проблемы
перевода текстов, такие как многозначность слов и синтаксических конструкций,
практическая невозможность глобального описания семантической структуры мира
даже в ограниченной предметной области, отсутствие эффективных формальных методов
описания лингвистических закономерностей и др.
Интерес к системам машинного перевода вновь был проявлен только к 70-м годам,
в период интенсивного развития теории искусственного интеллекта и теории «обучения
компьютеров пониманию языка», но только в 90-е — благодаря развитию систем искусственного
интеллекта, а также персональных компьютеров и появлению реального спроса на
машинный перевод — наступило реальное, а главное подкрепленное рыночными интересами
возрождение интереса к системам машинного перевода.
После того как машинный перевод превратился в коммерческий продукт, большие
усилия стали прилагаться к развитию функциональности системы, которая в программном
продукте играет роль, не меньшую, чем наличие хорошо разработанной лингвистической
базы.
На развитие машинного перевода стали выделяться крупные суммы. Так, за последние
15 лет только японские государственные организации потратили на решение этой
проблемы несколько сотен миллионов долларов.
В России подобных инвестиций в развитие систем машинного перевода не было,
однако отечественным компаниям, прежде всего компаниям PROMT и «Арсеналъ», удалось
добиться заметных успехов не только на российском, но и на мировом уровне. О
деятельности компании PROMT и ее последних продуктах мы и расскажем в данной
статье более подробно.
Философские обоснования
В 1960-х годах Станислав Лем обобщал высказывания о проблеме машинного перевода и связи с пониманием текста самой машиной (что связано, например, с обсуждением сформулированной в 1980 году концепции «китайской комнаты»):
| … мы настаиваем на наделении машин-переводчиков «полнотой внутренней жизни» человека; однако мы просто не знаем, в какой мере можно «недодать личность» машине, которая призвана хорошо переводить. Мы не знаем, можно ли «понимать», не обладая «личностью» хотя бы в зачатке. <…> Не представляется возможным эффективно использовать операциональный язык до конца в качестве орудия перевода в сфере языков дискурсивных — мыслительных. Либо машины будут действовать «понимающе», либо по-настоящему эффективных машин-переводчиков не будет вовсе. |