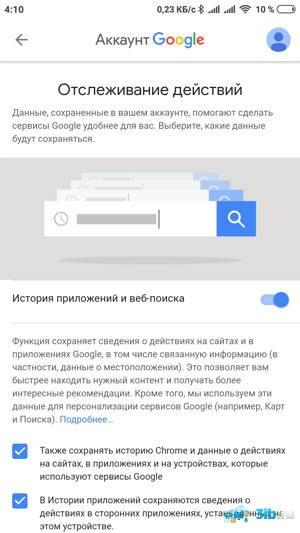
Распознавание речи
Содержание:
CMU Sphinx
Большая часть разработки CMU Sphinx ведется в университете Карнеги — Меллона. В разное время над проектом работали и Массачусетский технологический институт, и покойная ныне корпорация Sun Microsystems. Исходники движка распространяются под лицензией BSD и доступны как для коммерческого, так и для некоммерческого использования. Sphinx — это не пользовательское приложение, а, скорее, набор инструментов, который можно применить в разработке приложений для конечных пользователей. Sphinx сейчас — это крупнейший проект по распознаванию речи. Он состоит из нескольких частей:
- Pocketsphinx — небольшая быстрая программа, обрабатывающая звук, акустические модели, грамматики и словари;
- библиотека Sphinxbase, необходимая для работы Pocketsphinx;
- Sphinx4 — собственно библиотека распознавания;
- Sphinxtrain — программа для обучения акустическим моделям (записям человеческого голоса).
Проект развивается медленно, но верно. И главное — его можно использовать на практике. Причем не только на ПК, но и на мобильных устройствах. К тому же движок очень хорошо работает с русской речью. При наличии прямых рук и ясной головы можно настроить распознавание русской речи с помощью Sphinx для управления домашней техникой или умным домом. По сути, можно обычную квартиру превратить в умный дом, чем мы и займемся во второй части этого обзора. Реализации Sphinx имеются для Android, iOS и даже Windows Phone. В отличие от облачного способа, когда работа по распознаванию речи ложится на плечи серверов Google ASR или Яндекс SpeechKit, Sphinx работает точнее, быстрее и дешевле. И полностью локально. При желании можно научить Sphinx русской языковой модели и грамматике пользовательских запросов. Да, придется немного потрудиться при установке. Равно как и настройка голосовых моделей и библиотек Sphinx — занятие не для новичков. Так как основа CMU Sphinx — библиотека Sphinx4 — написана на Java, можно включать ее код в свои приложения для распознавания речи. Конкретные примеры использования будут описаны во второй части нашего обзора.
VoxForge
Особо выделим понятие речевого корпуса. Речевой корпус — это структурированное множество речевых фрагментов, которое обеспечено программными средствами доступа к отдельным элементам корпуса. Иными словами — это набор человеческих голосов на разных языках. Без речевого корпуса невозможна работа ни одной системы распознавания речи. В одиночку или даже небольшим коллективом создать качественный открытый речевой корпус сложно, поэтому сбором записей человеческих голосов занимается специальный проект — VoxForge.
Любой, у кого есть доступ к интернету, может поучаствовать в создании речевого корпуса, просто записав и отправив фрагмент речи. Это можно сделать даже по телефону, но удобней воспользоваться сайтом. Конечно, кроме собственно аудиозаписи, речевой корпус должен включать в себя дополнительную информацию, такую как фонетическая транскрипция. Без этого запись речи бессмысленна для системы распознавания.
VoxForge — стартовый портал для тех, кто хочет внести свой вклад в разработку открытых систем распознавания речи
Условия и ограничения
Распознавание речи — платная услуга, но Яндекс даёт 60 дней и 3000 ₽ для тестирования. За эти деньги можно распознать 83 часа аудио — больше трёх суток непрерывного разговора. Это очень много: за время подготовки этой статьи и тестирования технологии мы потратили 4 рубля за 3 дня.
Если отправлять файлы с записью больше минуты, то одна секунда аудио стоит одну копейку. Чтобы распознать запись длиной в час, нужно 36 рублей. Это примерно в 20 раз дешевле, чем берут транскрибаторы — люди, которые сами набирают текст на слух, прослушивая запись.
Нейросеть часто понимает, когда текст нужно разбить на абзацы, но делает это не всегда правильно. Ещё она не ставит запятые, тире и двоеточия. Максимум, что она делает — ставит точку в конце предложения и начинает новое с большой буквы. Но при этом почти все слова распознаются правильно, и отредактировать такой текст намного проще, чем набирать его с нуля.
Последнее — из-за особенностей нашей речи и произношения SpeechKit может путать слова, которые звучат одинаково (код — кот) или ставить неправильное окончание («слава обрушилось на него неожиданно»). Решение простое: прогоняем такой текст через орфонейрокорректор и всё в порядке. Одна нейронка исправляет другую — реальность XXI века
Всё, приступаем.
Иногда результат получается вот таким, но на понимание текста это не сильно влияет.
История
Первое устройство для распознавания речи появилось в 1952 году, оно могло распознавать произнесённые человеком цифры. В 1962 году на ярмарке компьютерных технологий в Нью-Йорке было представлено устройство IBM Shoebox.
В 1963 году в США были презентованы разработанные инженерами корпорации «Сперри» миниатюрные распознающие устройства с волоконно-оптическим запоминающим устройством под названием «Септрон» (Sceptron, но произносится без «к»), выполняющие ту или иную последовательность действий на произнесённые человеком-оператором определённые фразы. «Септроны» годились для применения в сфере фиксированной (проводной) связи для автоматизации набора номеров голосом и автоматической записи надиктовываемого текста телетайпом, могли применяться в военной сфере (для голосового управления сложными образцами военной техники), авиации (для создания «умной авионики», реагирующей на команды пилота и членов экипажа), автоматизированных системах управления и др. В 1983 году был презентован интерактивный комплекс «умной авионики» для ударных вертолётов «Апач», распознающий команды и запросы пилота, преобразующий их в сигналы управления на бортовое оборудование и односложно отвечающий ему голосом относительно возможности реализации поставленной им задачи.
Коммерческие программы по распознаванию речи появились в начале девяностых годов. Обычно их используют люди, которые из-за травмы руки не в состоянии набирать большое количество текста. Эти программы (например, Dragon NaturallySpeaking (англ.)русск., VoiceNavigator (англ.)русск.) переводят голос пользователя в текст, таким образом, разгружая его руки. Надёжность перевода у таких программ не очень высока, но с годами она постепенно улучшается.
Увеличение вычислительных мощностей мобильных устройств позволило и для них создать программы с функцией распознавания речи. Среди таких программ стоит отметить приложение Microsoft Voice Command, которое позволяет работать со многими приложениями при помощи голоса. Например, можно включить воспроизведение музыки в плеере или создать новый документ.
Все большую популярность применение распознавания речи находит в различных сферах бизнеса, например, врач в поликлинике может проговаривать диагнозы, которые тут же будут внесены в электронную карточку. Или другой пример. Наверняка каждый хоть раз в жизни мечтал с помощью голоса выключить свет или открыть окно. В последнее время в телефонных интерактивных приложениях все чаще стали использоваться системы автоматического распознавания и синтеза речи. В этом случае общение с голосовым порталом становится более естественным, так как выбор в нём может быть осуществлен не только с помощью тонового набора, но и с помощью голосовых команд. При этом системы распознавания являются независимыми от дикторов, то есть распознают голос любого человека.
Следующим шагом технологий распознавания речи можно считать развитие так называемых интерфейсов безмолвного доступа (silent speech interfaces, SSI). Эти системы обработки речи базируются на получении и обработке речевых сигналов на ранней стадии артикулирования. Данный этап развития распознавания речи вызван двумя существенными недостатками современных систем распознавания: чрезмерная чувствительность к шумам, а также необходимость четкой и ясной речи при обращении к системе распознавания. Подход, основанный на SSI, заключается в том, чтобы использовать новые сенсоры, не подверженные влиянию шумов в качестве дополнения к обработанным акустическим сигналам.
Особенности перевода голоса в текстовый формат
Как известно, попытки создать программы для распознавания голоса берут своё начало ещё в середине 20 века. Поначалу распознавание было довольно слабым, но использование более совершенных методов и технологий (скрытые марковские модели, нейронные сети etc.) подняло распознавание голоса на довольно высокий уровень.
Ныне мы можем встретить достаточное количество сетевых сервисов и программ, выполняющих перевод речи в текст. Практически все они хорошо распознают человеческий голос на многих языках (включая русский), и способны переводить его в текстовый формат. При этом 100% понимания речи достичь пока не удаётся, Это связано с шумами при звучании, невнятной дикцией или акцентом говорящего, помехами в работе микрофона, эмоциональным состоянием человека и другими схожими факторами.
При этом использование таких сервисов и программ позволяет существенно сэкономить время при наборе различных текстов. Вы можете быстро надиктовать нужный фрагмент после чего сохранить его в удобном текстовом формате на ваш компьютер или телефон.
Давайте разберёмся, какие сервисы и программы помогут быстро перевести речь в текст.
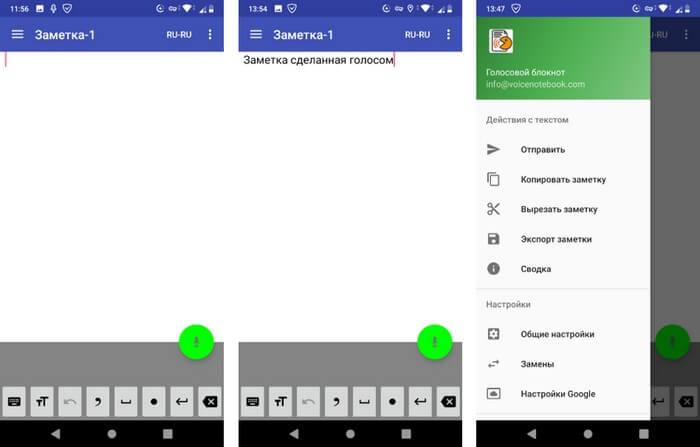
Голосовой блокнот — речь в текст на русском
Приложение «Голосовой блокнот» загружается на устройство с этой страницы Google Play. Для работы приложения требуется установка функции «Голосовой ввод от Google».
Для поддержки работы приложения без интернета установите локальный языковый пакет.
Вам также может быть интересно:
- Перевод голоса в текст — 7 способов
- Переводчик по фото онлайн — 5 способов
Возможности программы:
- Непрерывный режим диктовки.
- Поддержка управления заглавными буквами.
- Экспорт заметки в локальный файл на устройстве, или в «облако» в интернете.
- Импорт текстовых документов из файловых менеджеров и Google Диска.
- Вырезание и вставка заметок.
- Счетчик слов и символов.
- Откат последнего голосового ввода.
Работа в приложении проходит таким образом:
- Нажмите на кнопку голосового ввода (микрофон).
- Надиктуйте в смартфон заметку.
- Отредактируйте полученный текст.
- Нажмите на кнопку «Настройки» для дальнейших действий с этой заметкой.
Google Переводчик
В операционной системе Android распознавание речи в текст могут выполнить переводчики. Используйте соответствующее приложение или онлайн версию переводчика на веб-сайте в браузере, установленном на телефоне. Во втором случае, можно не использовать приложение, сохранив некоторую часть места и ресурсов на своем устройстве.
Перевести речь в текст можно следующим образом:
- Откройте Переводчик Google, выберите язык перевода, в нашем случае — русский язык.
- Нажмите на значок микрофона (Голосовой ввод).
- Предоставьте доступ к микрофону.
- Говорите, в окне переводчика отобразится ваш текст и перевод на английский язык.
Для того, чтобы воспользоваться переводом на русском языке, нажмите справа на переводимый язык «английский», а потом выберите русский язык. После этого, окно перевода станет на русском языке. Теперь вы можете скопировать перевод в нужное место.
Командная строка Яндекса
С её помощью мы сможем получать нужные ключи доступа, чтобы отправлять файлы с записями на сервер для обработки.
Весь процесс установки мы опишем для Windows. Если у вас Mac OS или Linux, то всё будет то же самое, но с поправкой на операционную систему. Поэтому если что — .
Для установки и дальнейшей работы нам понадобится PowerShell — это программа для работы с командной строкой, но с расширенными возможностями. Запускаем PowerShell и пишем там такую команду:
iex (New-Object System.Net.WebClient).DownloadString(‘https://storage.yandexcloud.net/yandexcloud-yc/install.ps1’)
Она скачает и запустит установщик командной строки Яндекса. В середине скрипт спросит нас, добавить ли путь в системную переменную PATH, — в ответ пишем Y и нажимаем Enter:
Командная строка Яндекса установлена в системе, закрываем PowerShell и запускаем его заново. Теперь нам нужно получить токен авторизации — это такая последовательность символов, которая покажет «Облаку», что мы — это мы, а не кто-то другой.
Переходим по специальной ссылке, которая даст нам нужный токен. Сервис спросит у нас, разрешаем ли мы доступ «Облака» к нашим данным на Яндексе — нажимаем «Разрешить». В итоге видим страницу с токеном:
Теперь нужно закончить настройку командной строки Яндекса, чтобы можно было с ней полноценно работать. Для этого в PowerShell пишем команду:
yc init
Когда скрипт попросит — вводим токен, который мы только что получили:
Сначала отвечаем «1», затем «Y» и «4».
Прямая расшифровка от Google
Приложение «Прямая расшифровка от Google» разработано для людей с ограниченными возможностями, в частности с нарушениями слуха. Программа автоматически распознает голос и звуки, выводит разговор на экран в виде текста.
Распознавание голоса на телефоне нам поможет перевести голос в текст, а результатом этого можно воспользоваться по своему усмотрению. Вы самостоятельно можете надиктовать текст в приложении, или получить в текстовом виде разговор со своим собеседником. Отвечать собеседнику можно с помощью клавиатуры или голосом.
Основные возможности приложения «прямая расшифровка от Google»:
- программа работает на мобильных устройствах, начиная с версии Android 5.0 (Lollipop);
- поддержка более 70 языков;
- поддержка внешних микрофонов;
- возможность ответа собеседнику с помощью экранной клавиатуры;
- виброотклик при начале разговора;
- расшифровка текста доступна только на вашем устройстве.
Установите программу из магазина Google Play по этой ссылке. После установки приложения, его необходимо активировать в настройках мобильного устройства.
На телефоне, работающем под управлением операционной системы Android 9 (Pie) это можно сделать следующим образом («чистый» Android):
- Войдите в настройки телефона.
- Выберите «Спец. возможности», нажмите на опцию «Прямая расшифровка».
- Предоставьте необходимые разрешения для этого приложения.
- В параметре «Use service» передвиньте кнопку переключателя в положение «Включено».
В нижнем правом углу экрана появится кнопка приложения в виде человечка с расставленными руками. Этот значок используется для запуска приложения «Прямая расшифровка» в любой программе на вашем мобильном устройстве.
Запустите приложение, войдите в настройки. Здесь можно выбрать подходящие параметры для работы приложения:
- размер шрифта;
- возможность для сохранения расшифровки в течение 3 дней;
- включить темную тему;
- выбрать основной и дополнительный язык;
- очистить историю;
- включить вибрацию при возобновлении речи;
- отмечать звуки, отличные от речи;
- скрывать непристойную лексику с помощью символов;
- показывать кнопку приостановки расшифровки.
Преобразование голоса в текст в приложении «Прямая расшифровка от Google» происходит следующим образом:
- Для запуска расшифровки голоса, нажмите на кнопку в нижней части экрана.
- Откроется окно приложения, в котором написано: «Готово к расшифровке».
- Начните говорить, речь отобразится в виде текста на экране смартфона.
Расстановка знаков пунктуации в русском языке не поддерживаются.
Распознанный текст можно скопировать в окно любой текстовой программы для дальнейшего редактирования или сохранить на устройстве в течении 3 дней, при условии, что включена данная опция. Отредактированный текст сохраните в файл на телефоне или отправьте адресату в мессенджер, в облачное хранилище, по электронной почте и т. д.
В приложении можно записывать телефонные разговоры.
Сравнительный тест сервисов
Для теста выберем два непростых для распознавания фрагмента, которые содержат нечасто употребляемые в нынешней речи слова и речевые обороты. Для начала читаем фрагмент поэмы «Крестьянские дети» Н. Некрасова.
Ниже представлен результат перевода речи в текст каждым сервисом (ошибки обозначены красным цветом):


Как видим, оба сервиса практически с одинаковыми ошибками справились с распознаванием речи. Результат весьма неплохой!
Теперь для теста возьмем отрывок из письма красноармейца Сухова (к/ф «Белое солнце пустыни»):


Отличный результат!
Как видим, оба сервиса весьма достойно справляются с распознаванием речи – выбирайте любой! Похоже что они даже используют один и тот же движок — уж слижком схожие у них оказались допущенные ошибки по результатам тестов ). Но если Вам необходимы дополнительные функции типа подгрузки аудио / видео файла и перевода его в текст (транскрибация) или синхронного перевода озвученного текста на другой язык, то Speechpad будет лучшим выбором!

Ну а это краткая видео инструкция по работе со Speechpad, записанная самим автором проекта:
Настраиваем доступ
Есть два способа работать с сервисом SpeechKit: через IAM-токен, который нужно запрашивать заново каждые 12 часов, или через API-ключ, который постоянный и менять его не нужно. Мы будем работать через ключ, потому что так удобнее.
Чтобы его получить, нам нужен сервисный аккаунт в «Облаке». Создадим его так.
1. Заходим в консоль управления и нажимаем на единственную папку в нашем облаке:
2. Выбираем «Сервисные аккаунты» → «Создать»:
3. Вводим имя (какое понравится), затем нажимаем «Добавить роль» и выбираем «editor»:
4. Заходим в сервисный аккаунт, который только что создали:
5. Нажимаем на кнопку «Создать новый ключ» и выбираем пункт «Создать API-ключ»:
Сервис спросит про описание — можно ничего не заполнять.
6. Сохраняем отдельно секретный ключ — он выдаётся только один раз и восстановить его нельзя. Выделяем, копируем и сохраняем в безопасное место:
Классификация систем распознавания речи
Системы распознавания речи классифицируются:
- по размеру словаря (ограниченный набор слов, словарь большого размера);
- по зависимости от диктора (дикторозависимые и дикторонезависимые системы);
- по типу речи (слитная или раздельная речь);
- по назначению (системы диктовки, командные системы);
- по используемому алгоритму (нейронные сети, скрытые Марковские модели, динамическое программирование);
- по типу структурной единицы (фразы, слова, фонемы, дифоны, аллофоны);
- по принципу выделения структурных единиц (распознавание по шаблону, выделение лексических элементов).
Для систем автоматического распознавания речи, помехозащищённость обеспечивается, прежде всего, использованием двух механизмов:
- Использование нескольких, параллельно работающих, способов выделения одних и тех же элементов речевого сигнала на базе анализа акустического сигнала;
- Параллельное независимое использование сегментного (фонемного) и целостного восприятия слов в потоке речи.
Методы и алгоритмы распознавания речи
«… очевидно, что алгоритмы обработки речевого сигнала в модели восприятия речи должны использовать ту же систему понятий и отношений, которой пользуется человек.»
Сегодня системы распознавания речи строятся на основе принципов признания[кем?]форм распознавания[неизвестный термин]. Методы и алгоритмы, которые использовались до сих пор, могут быть разделены на следующие большие классы:
Классификация методов распознавания речи на основе сравнения с эталоном.
Динамическое программирование — временные динамические алгоритмы (Dynamic Time Warping).
Контекстно-зависимая классификация.
При её реализации из потока речи выделяются отдельные лексические элементы — фонемы и аллофоны, которые затем объединяются в слоги и морфемы.
- Методы дискриминантного анализа, основанные на Байесовской дискриминации (Bayesian discrimination);
- Скрытые Марковские модели (Hidden Markov Model);
- Нейронные сети (Neural networks).
Архитектура систем распознавания
Одна из архитектур систем автоматической обработки речи, основанной на статистических данных, может быть следующей.
- Модуль шумоочистки и отделение полезного сигнала.
- Акустическая модель — позволяет оценить распознавание речевого сегмента с точки зрения схожести на звуковом уровне. Для каждого звука изначально строится сложная статистическая модель, которая описывает произнесение этого звука в речи.
- Языковая модель — позволяют определить наиболее вероятные последовательности слов. Сложность построения языковой модели во многом зависит от конкретного языка. Так, для английского языка, достаточно использовать статистические модели (так называемые N-граммы). Для высокофлективных языков (языков, в которых существует много форм одного и того же слова), к которым относится и русский, языковые модели, построенные только с использованием статистики, уже не дают такого эффекта — слишком много нужно данных, чтобы достоверно оценить статистические связи между словами. Поэтому применяют гибридные языковые модели, использующие правила русского языка, информацию о части речи и форме слова и классическую статистическую модель.
- Декодер — программный компонент системы распознавания, который совмещает данные, получаемые в ходе распознавания от акустических и языковых моделей, и на основании их объединения, определяет наиболее вероятную последовательность слов, которая и является конечным результатом распознавания слитной речи.
Этапы распознавания
- Обработка речи начинается с оценки качества речевого сигнала. На этом этапе определяется уровень помех и искажений.
- Результат оценки поступает в модуль акустической адаптации, который управляет модулем расчета параметров речи, необходимых для распознавания.
- В сигнале выделяются участки, содержащие речь, и происходит оценка параметров речи. Происходит выделение фонетических и просодических вероятностных характеристик для синтаксического, семантического и прагматического анализа. (Оценка информации о части речи, форме слова и статистические связи между словами.)
- Далее параметры речи поступают в основной блок системы распознавания — декодер. Это компонент, который сопоставляет входной речевой поток с информацией, хранящейся в акустических и языковых моделях, и определяет наиболее вероятную последовательность слов, которая и является конечным результатом распознавания.