Как работает js: управление памятью, четыре вида утечек памяти и борьба с ними
Содержание:
Типы адресов
Для идентификации переменных и команд используются символьные имена (метки), виртуальные адреса и физические адреса.
Виртуальные адреса
Виртуальные адреса вырабатывает компилятор. Так как не известно, в какое место оперативной памяти будет загружена программа, то компилятор присваивает переменным и командам виртуальные (условные) адреса, обычно считая по умолчанию, что программа будет размещена, начиная с нулевого адреса. Совокупность виртуальных адресов процесса называется виртуальным адресным пространством. Каждый процесс имеет собственное виртуальное адресное пространство.
Физические адреса
Физические адреса соответствуют номерам ячеек оперативной памяти, где в действительности расположены или будут расположены переменные и команды. Переход от виртуальных адресов к физическим может осуществляться двумя способами.
В первом случае замену виртуальных адресов на физические делает специальная системная программа — перемещающий загрузчик. Перемещающий загрузчик на основании имеющихся у него исходных данных о начальном адресе физической памяти, в которую предстоит загружать программу, и информации, предоставленной компилятором об адресно-зависимых константах программы, выполняет загрузку программы, совмещая ее с заменой виртуальных адресов физическими.
Второй способ заключается в том, что программа загружается в память в неизмененном виде в виртуальных адресах, при этом операционная система фиксирует смещение действительного расположения программного кода относительно виртуального адресного пространства. Во время выполнения программы при каждом обращении к оперативной памяти выполняется преобразование виртуального адреса в физический.
Второй способ является более гибким, он допускает перемещение программы во время ее выполнения, в то время как перемещающий загрузчик жестко привязывает программу к первоначально выделенному ей участку памяти. Вместе с тем использование перемещающего загрузчика уменьшает накладные расходы, так как преобразование каждого виртуального адреса происходит только один раз во время загрузки, а во втором случае — каждый раз при обращении по данному адресу.
Иногда (обычно в специализированных системах) заранее точно известно, в какой области оперативной памяти будет выполняться программа, и компилятор выдает исполняемый код сразу в физических адресах.
Принцип кэширования данных в ОС
Кэш-память — это способ организации совместного функционирования двух типов запоминающих устройств, отличающихся временем доступа и стоимостью хранения данных, который позволяет уменьшить среднее время доступа к данным за счет динамического копирования в «быстрое» ЗУ наиболее часто используемой информации из «медленного» ЗУ.
Кэш-памятью часто называют не только способ организации работы двух типов запоминающих устройств, но и одно из устройств — «быстрое» ЗУ. Оно стоит дороже и, как правило, имеет сравнительно небольшой объем
Важно, что механизм кэш-памяти является прозрачным для пользователя, который не должен сообщать никакой информации об интенсивности использования данных и не должен никак участвовать в перемещении данных из ЗУ одного типа в ЗУ другого типа, все это делается автоматически системными средствами.
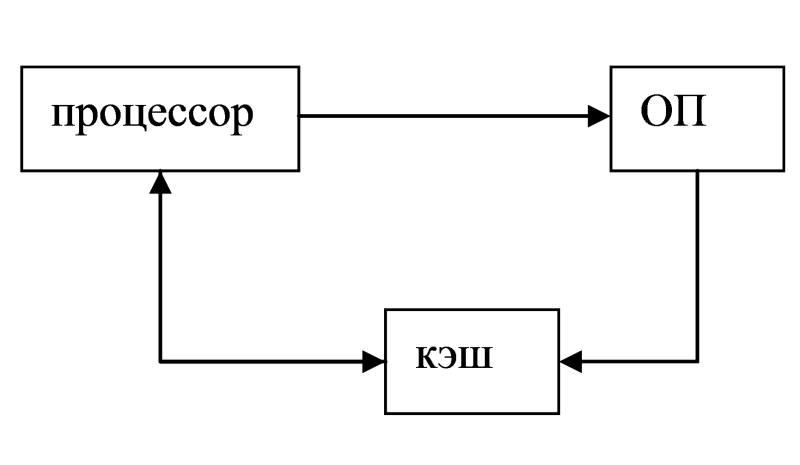
В системах, оснащенных кэш-памятью, каждый запрос к оперативной памяти выполняется в соответствии со следующим алгоритмом:
- Просматривается содержимое кэш-памяти с целью определения, не находятся ли нужные данные в кэш-памяти; кэш-память не является адресуемой, поэтому поиск нужных данных осуществляется по содержимому — значению поля «адрес в оперативной памяти», взятому из запроса.
- Если данные обнаруживаются в кэш-памяти, то они считываются из нее, и результат передается в процессор.
- Если нужных данных нет, то они вместе со своим адресом копируются из оперативной памяти в кэш-память, и результат выполнения запроса передается в процессор. При копировании данных может оказаться, что в кэш-памяти нет свободного места, тогда выбираются данные, к которым в последний период было меньше всего обращений, для вытеснения из кэш-памяти. Если вытесняемые данные были модифицированы за время нахождения в кэш-памяти, то они переписываются в оперативную память. Если же эти данные не были модифицированы, то их место в кэш-памяти объявляется свободным.
На практике в кэш-память считывается не один элемент данных, к которому произошло обращение, а целый блок данных, это увеличивает вероятность так называемого «попадания в кэш», то есть нахождения нужных данных в кэш-памяти.
t1{\displaystyle t_{1}\,\!} – время обмена процессора с ОП
t2{\displaystyle t_{2}\,\!} – время обмена процессора с КЭШем
t1>t2{\displaystyle t_{1}>t_{2}\,\!}
tcp=p2t2+(1−p1)t1{\displaystyle t_{cp}=p_{2}t_{2}+(1-p_{1})t_{1}\,\!}
Физическая и виртуальная память
Схема ячейки памяти
- Линия адреса (транзистор играет роль переключателя) — это то, что даёт доступ к конденсатору (линии данных).
- Когда в линии адреса появляется сигнал (красная линия), линия данных позволяет осуществлять запись данных в ячейку памяти, то есть — зарядку конденсатора, что даёт возможность сохранить в нём логическое значение, соответствующее 1.
- Когда сигнала в линии адреса нет (зеленая линия) конденсатор изолирован и его заряд не изменяется. Что бы записать в ячейку 0, необходимо выбрать её адрес и подать по линии данных логический 0, то есть соединить линию данных с минусом, тем самым разрядив конденсатор.
- Когда процессору нужно прочитать значение из памяти, сигнал подаётся по линии адреса (переключатель закрывается). Если конденсатор заряжен, то сигнал идёт по линии данных (считывается 1), в противном случае сигнал по линии данных не идёт (считывается 0).
Схема взаимодействия физической памяти и процессораЛинии шины адреса между процессором и физической памятью
- Каждому байту в оперативной памяти назначается уникальный числовой идентификатор (адрес). Надо отметить, что число присутствующих в памяти физических байтов не равно числу адресных линий.
- Каждая линия адреса может задавать 1-битовое значение, поэтому она указывает на один бит в адресе некоего байта.
- На нашей схеме имеется 32 линии адреса. В результате каждый адресуемый байт, в качестве адреса, использует 32-битное число. — младший адрес памяти. — старший адрес памяти.
- Так как каждый байт имеет 32-битный адрес, наше адресное пространство состоит из 232 адресуемых байт (4 Гб).
64Представление виртуального адресного пространстваУпрощённое представление взаимосвязи виртуальной и физической памяти
Увеличение динамически распределяемой памятиbrk
Контейнеры
В стандартной библиотеке языка C++ есть множество классов, которые облегчают работу с тем или иным видом объектов. И здесь это не реклама std, вы можете самостоятельно реализовать единожды необходимые вам контейнеры, а затем переиспользовать их неограниченное число раз
В первую очередь обратите внимание на следующие классы:
- Linked list — связный список
- Array — динамический/статический массив
- Queue — очередь
- Stack — стек
- Map — ассоциативный контейнер
- Set — множество
Почему я их упоминаю в статье про менеджмент памяти? Потому что они контролируют доступ к объектам внутри себя и исключают возможность memory corruption. Вызывая необходимые методы вы с легкостью сможете добавлять/удалять объекты, получать на них ссылки, итерироваться по ним, не задумываясь о том, где и как они лежат.
Общие идеи
Здесь мне бы хотелось уйти от конкретики к более абстрактным вещам, которые касаются не столько кода, сколько архитектуры и дизайна системы в целом. Ряд наблюдений, мыслей, которые мне удавалось увидеть/прочесть в том или ином источнике литературы за долгое время.
Основные объекты
Каков размер ? Программист, пишущий на C или C++, вероятно, скажет, что размер машинно-зависимого (machine-specific) — около 32 бит, возможно, 64; а следовательно, занимает не более 8 байтов. Но так ли это в Python?
Давайте напишем функцию, показывающую размер объектов (рекурсивно, если нужно):
Теперь с помощью этой функции можно исследовать размеры основных типов данных:
Если у вас 32-битный Python 2.7x, то вы увидите:
А если 64-битный Python 2.7x, то увидите:
Давайте сосредоточимся на 64-битной версии (в основном потому, что в нашем случае она более востребована). занимает 16 байтов. — 24 байта, в три раза больше по сравнению с в языке С, хотя это в какой-то мере machine-friendly целое число. Минимальный размер значений типа long (с неограниченной точностью), используемых для представления чисел больше 263 – 1, это — 36 байтов. Затем они увеличиваются линейно, как логарифм представляемого числа.
Числа с плавающей запятой в Python зависят от реализации, но похожи на числа с двойной точностью в C. Однако они не занимают всего лишь 8 байтов:
На 32-битной платформе выдаёт:
И на 64-битной:
Это опять втрое больше, чем предположил бы программист на C. А что насчёт строковых значений?
На 32-битной платформе:
И на 64-битной:
Пустое строковое значение занимает 37 байтов в 64-битной среде! Затем потребление памяти увеличивается в соответствии с размером (полезного) значения.
Давайте разберёмся и с другими часто востребованными структурами: кортежами, списками и словарями. Списки (реализованные как списки массивов, а не как связные списки, со ) — это массивы ссылок на Python-объекты, что позволяет им быть гетерогенными. Их размеры:
Пустой список занимает 72 байта. Размер пустого в 64-битном С — всего 16 байтов, в 4—5 раз меньше. Что насчёт кортежей? И словарей?
На 32-битной платформе выдаёт:
И на 64-битной:
Последний пример особенно интересен, потому что он «не складывается». Пары ключ/значение занимают 72 байта (их компоненты занимают 38 + 24 = 62 байта, а ещё 10 тратится на саму пару), но весь словарь весит уже 280 байтов (а не минимально необходимые 144 = 72 × 2 байта). Словарь считается эффективной структурой данных для поиска, и две вероятные реализации будут занимать памяти больше, чем необходимый минимум. Если это какое-то дерево, то приходится расплачиваться за внутренние ноды, содержащие ключ и два указателя на дочерние ноды. Если это хеш-таблица, то ради хорошей производительности нужно иметь место для свободных записей.
Эквивалентная (относительно) структура из C++ при создании занимает 48 байтов (пока ещё пустая). А пустое строковое значение в C++ требует 8 байтов (затем размер линейно растёт вместе с размером строки). Целочисленное значение — 4 байта (32 бит).
И что нам всё это даёт? Тот факт, что пустое строковое значение занимает 8 или 37 байтов, мало что меняет. Действительно. Но лишь до тех пор, пока ваш проект не начнёт разрастаться. Тогда вам придётся очень аккуратно следить за количеством создаваемых объектов, чтобы ограничить объём потребляемой приложением памяти. Для настоящих приложений это проблема. Чтобы разработать действительно хорошую стратегию управления памятью, нам нужно следить не только за размером новых объектов, но и за количеством и порядком их создания
Для Python-программ это очень важно. Давайте теперь разберёмся со следующим ключевым моментом: с внутренней организацией выделения памяти в Python
[править] Распределение неперемещаемыми разделами
Изображение:Ram 1.jpg
Суть: Есть ОС и оставшаяся физическая память. Оставшуюся физическую память делим на конкретное количество разделов. В каждом может быть свое задание и свой процесс. Внутри каждого раздела все аналогично рассмотренному выше примеру.
Необходимые аппаратные средства:
- Необходимо наличие 2 регистров границ, т.к. необходимо обеспечить корректность как по отношению к другим пользовательским разделам, так и по отношению к ОС.
- Ключи защиты (PSW). Каждый раздел имеет свой ключ защиты, который проверяется при всех операциях чтения\записи.
Недостатки:
- Перегрузка регистра границ при каждой смене контекста;
- Сложности при использовании каналов/процессоров ввода/вывода. Если процесс попытается читать не из своей области, то это тяжело отловить. Эту проблему решают Ключи защиты.
Алгоритмы: Модель статического определения разделов.
А. Много входных очередей процессов.
Сортировка входной очереди процессов по отдельным очередям к разделам. Вся очередь процессов разбивается на к очередей, с каждой из которых связан свой раздел. Процесс размещается в разделе минимального размера, достаточного для размещения данного процесса. В случае отсутствия процессов в каких-то под очередях – неэффективность использования памяти.
Недостаток: Может возникнуть ситуация, когда очередь больших процессов пуста, а в очереди маленьких процессов очень много процессов. А перегрузить мы не сможем.
Б. Одна входная очередь процессов.
- При освобождении раздела – поиск (в начале очереди) первого процесса, который может разместиться в разделе. Проблема: большие разделы маленькие процессы. Это несправедливо по отношению к большим процессам.
- При освобождении раздела – поиск процесса максимального размера, не превосходящего размер раздела. Проблема: дискриминация “маленьких” процессов.
- Оптимизация варианта 2. Каждый процесс имеет счетчик дискриминации. Если значение счетчика процесса >= K, то обход его в очереди невозможен.
Достоинства:
- Простое средство организации мультипрограммирования.
- Простые средства аппаратной поддержки.
- Простые алгоритмы.
Недостатки:
- Внешняя Фрагментация.
- Ограничение размерами физической памяти как внутри одного раздела, так и в целом
- Весь процесс размещается в памяти – возможно неэффективное использование и внутренняя фрагментация.
Средство выделения памяти Go
здесьКлассы размеров в GoСтраница размером 8 Кб разделена на блоки, соответствующие классу размера 1 Кб
▍Структура mcache
Взаимодействие между логическим процессором, mcache и mspan в Go
- Объект scan — это объект, который содержит указатель.
- Объект noscan — это объект, в котором нет указателя.
▍Структура mcentral
- Список объектов mspan, в которых нет свободных объектов, или тех mspan, которые имеются в mcache.
- Список объектов mspan, в которых есть свободные объекты.
Структура mcentral
▍Структура mheap
Структура mheap
- — это массив spanList. Структура mspan в каждом spanList состоит из 1 ~ 127 (_MaxMHeapList - 1) страниц. Например, free — это связанный список структур mspan, содержащих 3 страницы. Слово «free» в данном случае указывает на то, что речь идёт о пустом списке, память в котором не выделена. Список может быть, в противоположность пустому, списком, в котором память выделена (busy).
- — это список свободных структур mspan. Количество страниц на элемент (то есть, mspan) более 127. Для поддержки такого списка используется структура данных mtreap. Список занятых структур mspan называется busylarge.
Pickle
Кстати, а что насчёт ?
Pickle — стандартный способ (де)сериализации Python-объектов в файл. Каково его потребление памяти? Он создаёт дополнительные копии данных или работает умнее? Рассмотрим короткий пример:
При первом вызове мы профилируем создание pickled-данных, а при втором вызове заново считываем их (можно закомментировать функцию, чтобы она не вызывалась). При использовании в ходе создания данных потребляется много памяти:
А при считывании — немного меньше:
C другой стороны, десериализация выглядит более эффективной. Потребляется больше памяти, чем исходный список (300 Мб вместо 230), но это хотя бы не вдвое больше.
В целом лучше избегать (де)сериализации в приложениях, чувствительных к потреблению памяти. Какие есть альтернативы? Сериализация сохраняет всю структуру данных, так что позднее вы сможете полностью восстановить её из получившегося файла. Но это не всегда нужно. Если файл содержит список, как в предыдущем примере, то, возможно, целесообразно использовать простой, текстовый формат. Давайте посмотрим, что это даёт.
Простейшая (naïve) реализация:
Создаём файл:
Считываем файл:
При записи потребляется гораздо меньше памяти. Всё ещё создаётся много временных маленьких объектов (примерно 60 Мб), но это не сравнить с удвоенным потреблением. Чтение сравнимо по затратам (используется чуть меньше памяти).
Этот пример тривиален, но он обобщает стратегии, при которых вы сначала не загружаете данные целиком с последующей обработкой, а считываете несколько элементов, обрабатываете их и заново используете выделенную память. Загружая данные в массив Numpy, к примеру, можно сначала создать массив Numpy, затем построчно считывать файл, постепенно заполняя массив. Это позволит разместить в памяти только одну копию всех данных. А при использовании данные будут размещены в памяти (как минимум) дважды: один раз , второй раз при работе с Numpy.
Или, ещё лучше, применяйте массивы Numpy (или PyTables). Но это уже совсем другая история. В то же время в директории Theano/doc/tutorial вы можете почитать другое руководство по загрузке и сохранению.
Цели архитектуры Python никак не совпадают, допустим, с целями архитектуры C. Последний спроектирован так, чтобы дать вам хороший контроль над тем, что вы делаете, за счёт более сложного и явного программирования. А первый спроектирован так, чтобы вы могли писать код быстрее, но при этом язык прячет большинство подробностей реализации (если не все). Хотя это звучит красиво, но игнорирование неэффективных реализаций языка в production-среде порой приводит к неприятным последствиям, иногда неисправимым. Надеюсь, что знание этих особенностей Python при работе с памятью (архитектурных особенностей!) поможет вам писать код, который будет лучше соответствовать требованиям production, хорошо масштабироваться или, напротив, окажется горящим адом для памяти.
Pre-allocating
Заранее получить всю необходимую память для работы программы, разместить в ней необходимые объекты и/или распределять эту память под свои нужды уже в процессе работы.
Преимущество такого подхода очевидно: никаких запросов malloc/free на выделение памяти в течение работы. Отсюда вытекает и тот факт, что ОС не скажет вам «run out of memory», т.к все необходимое вы получили заранее и не более. Теперь вы сможете работать с памятью в том стиле, который требуется для решения ваших задач (выравнивание, попадание в кэш, упаковка данных подряд и т.д).
Но такой подход очень сложен в реализации. Он требует ручного распределения памяти среди всех объектов вашей системы. Более того, вы неизбежно можете столкнуться с перерасходом и большим кол-вом неиспользуемой памяти. Если ваша система будет делать множество динамических аллокаций в процессе работы, то такой подход неизбежно приведет ко всем тем проблемам с malloc/free, которые были озвучены ранее: фрагментация, долгие вызовы, нехватка памяти.
Алгоритм «пометь и выброси»
- Сборщик мусора строит список «корневых объектов». Такие объекты обычно являются глобальными переменными, ссылки на которые имеются в коде. В JavaScript примером глобальной переменной, которая может играть роль корневого объекта, является объект .
- Все корневые объекты просматриваются и помечаются как активные (то есть, это не «мусор»). Также, рекурсивно, просматриваются все дочерние объекты. Всё, доступ к чему можно получить из корневых объектов, «мусором» не считается.
- Все участки памяти, не помеченные как активные, могут быть признаны подходящими для обработки сборщиком мусора, который теперь может освободить эту память и вернуть её операционной системе.
Визуализация алгоритма «пометь и выброси»этом
Состояния процесса в ОС
Состояние процесса в ходе жизненного цикла в ОС
Эти состояния:
- ВЫПОЛНЕНИЕ: активное состояние процесса, во время которого процесс обладает всеми необходимыми ресурсами и непосредственно выполняется процессором.
- ГОТОВНОСТЬ: также пассивное состояние процесса, но в этом случае процесс заблокирован в связи с внешними по отношению к нему обстоятельствами: процесс имеет все требуемые для него ресурсы, он готов выполняться, однако процессор занят выполнением другого процесса.
- ОЖИДАНИЕ: пассивное состояние процесса, процесс заблокирован, он не может выполняться по своим внутренним причинам, он ждет осуществления некоторого события, например, завершения операции ввода-вывода, получения сообщения от другого процесса, освобождения какого-либо необходимого ему ресурса.
В ходе жизненного цикла каждый процесс переходит из одного состояния в другое в соответствии с алгоритмом планирования процессов, реализуемым в данной операционной системе.
В состоянии ВЫПОЛНЕНИЕ в однопроцессорной системе может находиться только один процесс, а в каждом из состояний ОЖИДАНИЕ и ГОТОВНОСТЬ — несколько процессов, эти процессы образуют очереди соответственно ожидающих и готовых процессов. Жизненный цикл процесса начинается с состояния ГОТОВНОСТЬ, когда процесс готов к выполнению и ждет своей очереди. При активизации процесс переходит в состояние ВЫПОЛНЕНИЕ и находится в нем до тех пор, пока либо он сам освободит процессор, перейдя в состояние ОЖИДАНИЯ какого-нибудь события, либо будет насильно «вытеснен» из процессора, например, вследствие исчерпания отведенного данному процессу кванта процессорного времени. В последнем случае процесс возвращается в состояние ГОТОВНОСТЬ. В это же состояние процесс переходит из состояния ОЖИДАНИЕ, после того, как ожидаемое событие произойдет.
Информация о процессе:
-
- Режим работы процессора.
- Информация об открытых файлах.
- Регистры.
- Состояние внешних устройств.
- Операции ввода – вывода.
Информационные структуры описывающие процессы
Существует две информационные структуры по-разному описывающие процессы — контекст процесса и дескриптор процесса.
Контекст процесса
Контекст процесса содержит информацию о внутреннем состоянии процесса, а также отражает состояние аппаратуры в момент прерывания процесса и включает параметры операционной среды. Содержит часть информации необходимой для возобновления выполнения процесса с прерванного места.
В состав контекста процесса входит:
- содержимое регистров процессора (включает счётчик команд, т.е. на каком этапе находится процесс);
- размещение кодового сегмента;
- информацию об открытых данным процессом файлах;
- информацию о работах с внешними устройствами (+ коды ошибок выполненных процессором, системных вызовов, незавершенных операциях ввода-вывода).
Дескриптор процесса
Дескриптор процесса – это информационная структура, которая описывает внешнюю структуру (информацию) процессе (нужна планировщику для выполнения процесса, а так же нужна ядру в течение всего жизненного цикла процесса)
В состав дескриптора входят:
- Идентификатор процесса;
- Состояние процесса.
- Информация о привилегированности процесса.
- Информация о расположении кодового сегмента.
Дескрипторы присутствуют в качестве элементов списка. Для того, чтобы ОС выбирала процессы надо иметь идентификаторы процессов и т.д., т.е. дескрипторы. Дескрипторы отдельных процессов объединены в список, образующих таблицу процессов. Память для таблицы процессов отводиться динамически в области ядра. На основании соседних в таблице процессов ОС осуществляет планирование и синхронизацию процессов. Потоки образуют очереди готовых и ожидающих потоков путём объединения в списки дескрипторов отдельных потоков. Такая организация очередей позволяет легко их переупорядочить, включать и исключать процессы, переводить процессы из одного состояния в другое.
Механизм работы
В самом простом и наиболее распространенном случае страничной организации памяти (или paging) как логическое адресное пространство, так и физическое представляются состоящими из наборов блоков или страниц одинакового размера. При этом образуются логические страницы(page), а соответствующие единицы в физической памяти называют физическими страницами или страничными кадрами (page frames).Страницы (и страничные кадры) имеют фиксированную длину, обычно являющуюся степенью числа 2, и не могут перекрываться. Каждый кадр содержит одну страницу данных. При такой организации внешняя фрагментация отсутствует, а потери из-за внутренней фрагментации, поскольку процесс занимает целое число страниц, ограничены частью последней страницы процесса.
Логический адрес в страничной системе – упорядоченная пара (p,d), где p – номер страницы в виртуальной памяти(селектор), а d – смещение в рамках страницы p, на которой размещается адресуемый элемент. Разбиение адресного пространства на страницы осуществляется вычислительной системой незаметно для программиста. Поэтому адрес является двумерным лишь с точки зрения операционной системы, а с точки зрения программиста адресное пространство процесса остается линейным. На самом деле адрес в памяти также можно указать другими способами — через константы и значения переменных, но всегда используется пара значений p и d, в явном или неявном виде. Каждый раз, при выполнении команды, процессор производит преобразование логического адреса в линейный адрес — 32-разрядный абсолютный адрес в памяти. После вычисления линейного адреса процессор преобразует его в физический адрес, по которому и производит обращение к памяти.
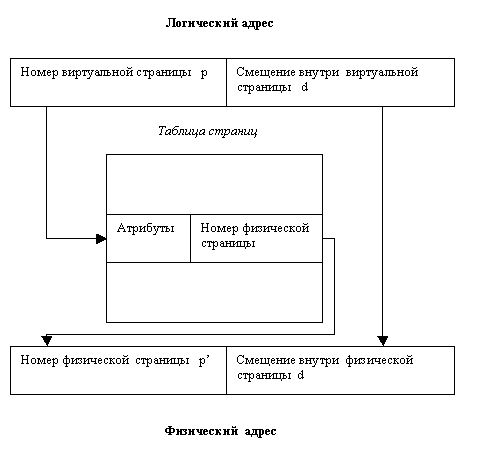
Преобразование адресов в страничной памяти
Описываемая схема позволяет загрузить процесс, даже если нет непрерывной области кадров, достаточной для размещения процесса целиком.
Число записей в одной таблице ограничено и зависит от размера записи и размера страницы. Используется многоуровневая организация таблиц, часто 2 или 3 уровня, иногда 4 уровня (для 64-разрядных архитектур).
Основное применение страничного преобразования адреса — организация виртуальной памяти. Виртуальная память позволяет использовать программы, требующие больший объем памяти, чем установленный на компьютере физический объем памяти. Остальная информация может быть сброшена на внешний носитель.
Управление страничным разбиением памяти обычно возлагается на специальную микросхему MMU (Memory Managment Unit — устройство управления памятью). В микропроцессоре i80486 и выше это устройство встроено в процессор.
Как и сегментация, страничная организация памяти связана с преобразованием виртуального адреса (в данном случае линейного) в физический. В страничном преобразовании базовым объектом памяти является блок фиксированного размера, называемый страницей (page).
В процессе страничного преобразования старшие 20 бит 32-х битного линейного адреса заменяются новым значением — номером физической страницы. Младшие же 12 бит линейного адреса определяют положение байта внутри страницы и остаются неизменными.
Для уменьшения размера таблицы страниц в микропроцессорах x86 предусмотрена двухуровневая схема преобразования адреса. Основой страничного преобразования служит регистр управления CR3, содержащий 20-ти битный физический базовый адрес каталога страниц текущей задачи. Предполагается, что каталог выровнен по границе страничного кадра, постоянно находится в памяти и не участвует в свопинге.
Корневая страница, называемая каталогом страниц, содержит 1024 32-х битных дескриптора, называемых элементами каталога страниц PDE (Page Directory Entry). Каждый из них адресует подчиненную таблицу страниц. Каждая из этих таблиц содержит 1024 32-х битных дескриптора, называемая элементами таблицы страниц. PTE (Page Table Entry). Каждый PTE содержит адрес страничного кадра в физической памяти.
Собственно преобразование линейных адресов в физические состоит из следующих действий:
- Старшие 10 бит 31 — 22 линейного адреса, дополненные двумя младшими нулями, служат индексом PDE.
- Средние 10 бит 21 — 12 линейного адреса, дополненные двумя младшими нулями, индексируют таблицу страниц PTE. Элемент PTE содержит 20-битный базовый адрес страничного кадра в физической памяти.
Этот базовый адрес из элемента PTE объединяется с младшими 12-ю битами линейного адреса, образуя 32-х битный физический адрес.
Заключение
Итак, нужно ли вам делать чистку внутренней памяти? Ответ прост – нет! Вам нужно лишь принять меры тогда, когда ваш телефон станет работать медленнее. В целом, Android-девайсы могут самостоятельно управлять RAM-памятью на оптимальном уровне. Закрытие приложений в общем списке приложений может улучить общую функциональность устройства, но это не имеет ничего общего с оптимизацией и эффективностью оперативной памяти.
На наш взгляд, автоматическое управление RAM-памятью Android-девайса – это самая быстрая и эффективная система, которую вы могли бы пожелать. Так что оставьте управление памятью самой ОС Android, и она вас не подведет