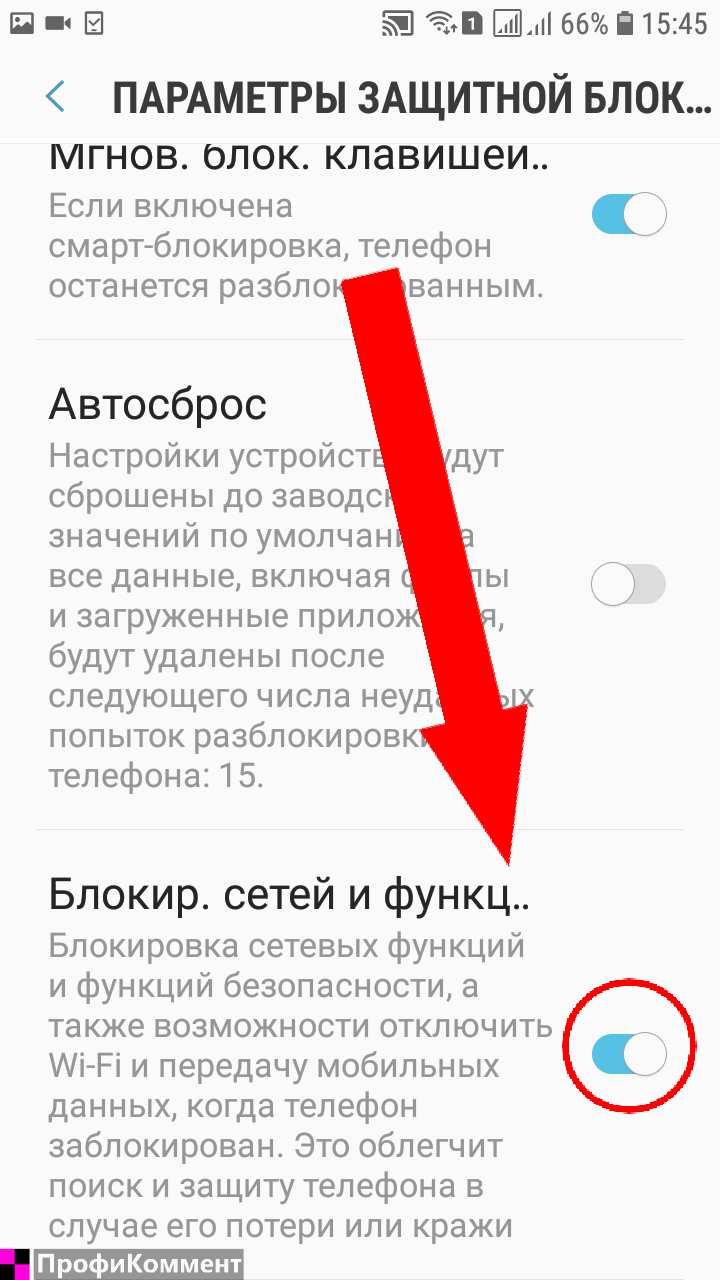
Как писать конспекты, если ты программист
Содержание:
- Где можно распознать текст с PDF файла, картинки или фотографии бесплатно
- Сделать свой русский рукописный шрифт
- Fontedge.matton.se – узнавание шрифта онлайн
- Узнать шрифт по картинке онлайн – особенности реализации
- Классификация по расстоянию до ближайшего соседа
- N-Tech Lab
- Алгоритмы распознавания лиц на изображении
- Писец 2.0
- Редактируйте любые PDF-файлы легко и быстро
- VisionLabs Luna
- Классификация по ближайшему среднему значению
- Синяки на лице – отчего и почему?
- Как это обычно делают?
- #1. PDFelement Pro
- Методы распознавания образов
Где можно распознать текст с PDF файла, картинки или фотографии бесплатно
Итак, вот список сервисов:
www.newocr.com – позволяет распознать текст бесплатно с изображений таких форматов как: JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu. Сервис поддерживает множество языков. После распознания текста с картинки, его можно скопировать и вставить в свой документ.
www.onlineocr.net — аналогичный предыдущему сервис, с тем лишь отличием, что здесь распознанный текст можно скачать в форматах Microsoft Word (docx), Microsoft Exel (xlsx), Text Plain (txt).
www.free-ocr.com – сервис, поддерживающий форматы jpg, png, bmp, pdf, jpeg, tiff, tif и gif. Языков распознавания чуть меньше чем в предыдущих сервисах, но тоже немало. Скачать распознанный тест можно в txt формате.
www.i2ocr.com – сервис, поддерживающий более 60 языков. Кроме основной функции распознавания текста с изображений, здесь есть такие инструменты как:
- Конвертация web-страницы в PDF;
- Преобразование web-страницы в изображение (скриншот);
- Генератор кнопок CSS3;
- Международные клавиатуры;
- Преобразователь формата изображений;
Качество извлечения текста с изображений
Особой разницы в качестве распознавания текста на изображениях между сервисами я не заметил, поэтому в качестве примера покажу лишь первый сервис.
Для примера я взял несколько изображений разного размера и качества изображенного текста.
Изображение 1 (790 X 588 px)
Изображение 2 (793 X 1024 px)
Изображение 3 (600 X 350 px)
И вот результат самого текста, который сервис распознал на картинке.
Результат 1 изображения:
В первом изображении текст распознан идеально и вообще без ошибок.
Результат 2 изображения:
Здесь видно присутствие ошибок. Это связано с особенностю шрифта и контрастом текста на основном фоне.
Результат 3 изображения:
В третьем примере левая часть столбца имееет плохую контрастность, поэтому некоторы слова вообще не распознаны.
На основе этих трех примеров, можно сделать простой вывод – чем лучше и отчетливее виден текст на изображении, тем более качественное будет распознавание текста. Многое так же зависит от шрифта текста. Если шрифт простой, то его сервис прочтет без труда, ну а чем сложнее шрифт, тем больше будет ошибок при распознавании текста.

Каролина Цветков
Jul 26,2019 • Filed to: Файлы OCR PDF
Оптическое распознавание символов (англ. Optical Character Recognition – OCR) это новейший метод механического перевода, который преобразует изображения рукописного текста в редактируемый текст на вашем компьютере. Например, он может сделать обычный PDF с отсканированного файла с помощью OCR или PDF на основе изображения, или преобразует рукописный текст в печатный. Технология была разработана в 1933 году, и с каждым годом развивалась. В настоящее время инструменты OCR способны выполнять огромную работу в преобразовании газет, писем, книг и любых других печатных или рукописных материалов в компьютерные редактируемые тексты.
Технология распознавания OCR рукописных текстов в настоящее время используется в больших масштабах, при этом уровень точности транскрипции растет день ото дня, и она уже близка к совершенству. В настоящее время, вы можете просто взять рецепт от врача и использовать технологию OCR, чтобы расшифровать его. Это невероятно!
Сделать свой русский рукописный шрифт
Но, скачав эти шрифты, стало понятно, что никто не поверит, будто мы пишем, как Пушкин, Боярский или Моцарт. Поэтому пришлось сделать рукописный шрифт самим. Но как сделать свой шрифт, как две капли воды похожий на ваш обычный почерк?
Для начала устанавливаем Font Creator 6. Далее, на чистом листе (в линейку и в клетку не подойдут) пишем все буквы русского (английского, и других при необходимости) алфавита, а также цифры и спец. символы.Сканируем получившееся творение. Далее режем отсканенную картинку на отдельные буковки и циферки (фотошоп или банально пэйнт подойдет), называем соответственно.
Следующий этап в Font Creator:- Нажимаем файл — новый (New)- Даем название своему рукописному шрифту (например Moy_shrift), ставим отметку на Unicode, на Regular и на Don’t include outlines (для чистого бланка силуэтов), короче, все по умолчанию.- Перед вами появляется панель с силуэтами знаков препинания и английских букв. Вам необходимо вставить в нее Кириллицу. Поступаем следующим образом:1. Нажимаем в верхней строке Вставка (Insert), выбираем Символ (Characters), ДА.2. Перед вами появляется таблица символов первого шрифта в вашей базе, Затем листаем страницы таблицы кнопкой Block→.3. Находим русские буквы.5. Смотрим индекс первой буквы А (у меня $0410) в поле Выбранный Символ (Selected Character).6. Смотрим индекс буквы я (у меня $044F)7. В поле Добавьте эти символы (Add these character… ) вводим эти числа (как $0410-$044F).8. Нажимаем Ok.9. Ваш шаблон пополнился соответствующими силуэтами Кириллицы.
10. Так же вы по отдельности можете вставить туда интересующие вас знаки (Ё,ё и пр.)Теперь нажимаем на силуэт буквы которую хотите сотворить правой кнопкой мыши.Затем выбираете пункт импорт изображения (Import image).В разделе Import image вы нажимаете на кнопку Загрузить (Load).В следующем окне вы открываете папку, в которой сохранили написанные буквы и символы.В окне появится изображение этой буквы, нажимаем на кнопку Generate.Вот ваша буковка и появилась.Два раза нажимаем на квадратик с вашей буковкой (квадратик в котором раньше был силуэт этой буквы). Перед вами открывается разлинеенное окошечко. Не пугайтесь большого количества красных пунктирных полосочек, все они вам пригодятся.Для удобства разверните окно на весь экран.
Если ваша буква чересчур большая или маленькая, то удаляем уже загруженную, загружаем новую и, не нажимая генерировать, жмем на вкладку Глиф. Тут выбираем подходящий множитель (это уже методом тыка) и жмем «использовать по умолчанию».
Далее разберемся с двумя главными линиями (это в разлинеенном окошке) – левая и правая — они определяют то, как будут соприкасаться буквы вашего рукописного шрифта между собой. Если надо, чтобы буквы соприкасались (как в рукописи), правую линию передвиньте на букву (чтобы она чуть-чуть вылазила за линию).Самая нижняя линия (Win Descent) – максимальный предел для букв с хвостиком (ц,у,щ,з,р,д). Если необходимо, можно ее опустить:Вторая снизу линия (Baseline)– линия опоры каждой буквы. Если ваши буквы будут по разному стоять на этой линии, то соответственно и в Ворде у вас все будет плясать.Третья снизу линия (x-Height) – максимальная высота маленьких букв.Четвертая (CapHeight) – максимальная высота больших букв, цифр, а также буквы «в», и может быть для кого-то «д» и «б». И пятая снизу линия – линия края верхней строки. (по-моему =)
Под все эти линию буквы необходимо точно подогнать, иначе символы шрифта будут разнобойными.
Ну, собственно, почти все. Теперь сохраняем ваш рукописный шрифт, копируем (через мой компьютер или проводник) в папку Fonts, что на С диске, в папке Windows (может быть скрытой), запускаем ворд, находим свое творение и наслаждаемся.
Fontedge.matton.se – узнавание шрифта онлайн
Сервис fontedge.matton.se по своему поисковому инструментарию похож на описанные выше аналоги. При этом его функционал работает достаточно нестабильно, потому мы поместили его в конец нашего списка.
Работа с сервисом состоит примерно в следующем:
- Загрузите изображение с нужным шрифтом на ресурс;
- Кликните на букве с опознаваемого слова;
- Проверьте, правильно ли опознана нужная буква;
-
Внесите букву в идентификационный список;
Функционал ресурса fontedge.matton.se
- Повторите операцию для ещё нескольких различных букв;
- Заполните буквенное поле;
- Кликните на стрелку запуска идентификации;
- Просмотрите полученные результаты.
Узнать шрифт по картинке онлайн – особенности реализации
Для реализации данной задачи можно воспользоваться рядом сетевых ресурсов (преимущественно англоязычных), которые я перечислю ниже. Работа с ними довольно шаблонна: вы переходите на такой онлайн-ресурс, загружаете на него картинку с нужным вам шрифтом (или указываете на такую картинку ссылку в сети), при необходимости отмечаете нужный для распознавания текст. Также некоторые ресурсы могут запросить определение ещё нескольких параметров (к примеру, имеет ли текст утолщения), после чего происходит распознавание нужного шрифта.
После прохождения процедуры распознавания шрифта сайт предложит вам визуально определить, правильно ли распознаны цифры и буквы (при необходимости будет нужно провести самостоятельную корректировку, указав правильный символ). После этого сайт выдаст вам ряд названий схожих визуально шрифтов, а некоторые продвинутые ресурсы предложат скачать понравившийся шрифт к себе на ПК.
При этом учтите, что шрифт на картинке должен находиться в горизонтальном положении, символы должны быть качественно отделены друг от друга. И иметь достаточную высоту (при необходимости используйте Photoshop или другой визуальный редактор для подгонки текста под указанные требования). Вам может быть полезна статья по уменьшению шрифта на компьютере с помощью клавиатуры.
Распознать нужный шрифт иногда бывает довольно тяжело
Классификация по расстоянию до ближайшего соседа
Другой подход при классификации заключается в отнесении неизвестного вектора признаков x к тому классу, к отдельному образцу которого этот вектор наиболее близок. Это правило называется правилом ближайшего соседа. Классификация по ближайшему соседу может быть более эффективна, даже если классы имеют сложную структуру или когда классы пересекаются.
При таком подходе не требуется предположений о моделях распределения векторов признаков в пространстве. Алгоритм использует только информацию об известных эталонных образцах. Метод решения основан на вычислении расстояния x до каждого образца в базе данных и нахождения минимального расстояния. Преимущества такого подхода очевидны:
- в любой момент можно добавить новые образцы в базу данных;
- древовидные и сеточные структуры данных позволяют сократить количество вычисляемых расстояний.
Кроме того, решение будет лучше, если искать в базе не одного ближайшего соседа, а k. Тогда при k > 1 обеспечивает наилучшую выборку распределения векторов в d-мерном пространстве. Однако эффективное использование значений k зависит от того, имеется ли достаточное количество в каждой области пространства. Если имеется больше двух классов то принять верное решение оказывается сложнее.
N-Tech Lab
ÐÑÐ½Ð¾Ð²Ð½Ð°Ñ ÑÑаÑÑÑ: N-Tech Lab
РоÑÑийÑÐºÐ°Ñ ÐºÐ¾Ð¼Ð¿Ð°Ð½Ð¸Ñ N-Tech Lab бÑла оÑнована в 2015 Ð³Ð¾Ð´Ñ Ð¸ занимаеÑÑÑ ÑаÑпознаванием Ð»Ð¸Ñ Ñ Ð¿Ð¾Ð¼Ð¾ÑÑÑ Ð½ÐµÐ¹ÑоннÑÑ ÑеÑей. РдекабÑе 2015 года алгоÑиÑм FaceN занÑл пеÑвое меÑÑо в миÑовом ÑемпионаÑе по ÑаÑÐ¿Ð¾Ð·Ð½Ð°Ð²Ð°Ð½Ð¸Ñ Ð»Ð¸Ñ The MegaFace, ÑÑмев обойÑи ÑазÑабоÑÑиков . Ðадание заклÑÑалоÑÑ Ð² Ñом, ÑÑÐ¾Ð±Ñ Ð²ÑделиÑÑ Ð² миллионной базе ÑоÑогÑаÑий изобÑÐ°Ð¶ÐµÐ½Ð¸Ñ Ð¾Ð´Ð½Ð¸Ñ Ð¸ ÑÐµÑ Ð¶Ðµ лÑдей.
Ðо Ñловам пÑедÑÑавиÑелей компании, ÑазÑабоÑаннÑй алгоÑиÑм позволÑÐµÑ ÑаÑпознаваÑÑ ÑоÑогÑаÑии даже лÑÑÑе Ñеловека. Ðомимо ÑÑадиÑионнÑÑ Ð¸Ð½Ð²Ð°ÑианÑнÑÑ Ð¿Ñизнаков (велиÑина глаз, ÑÐ°Ð·Ð¼ÐµÑ Ð³Ñб и Ñ.д.), ÑиÑÑема наÑÐ¾Ð´Ð¸Ñ Ñакие инваÑианÑнÑе пÑизнаки, коÑоÑÑй ÑеловеÑеÑкий глаз вÑделиÑÑ Ð½Ðµ ÑпоÑобен.
Ð ÑевÑале 2016 ÐºÐ¾Ð¼Ð¿Ð°Ð½Ð¸Ñ Ð·Ð°Ð¿ÑÑÑила новÑй пÑÐ¾ÐµÐºÑ FindFace, коÑоÑÑй, иÑполÑзÑÑ Ð°Ð»Ð³Ð¾ÑиÑм FaceN, позволÑÐµÑ Ð½Ð°ÑодиÑÑ Ð¿Ð¾ ÑоÑогÑаÑии пÑоÑили полÑзоваÑелей в ÑоÑиалÑной ÑеÑи «ÐконÑакÑе».
Алгоритмы распознавания лиц на изображении
Стоит отметить, что коммерциализация продуктов данного сектора стала возможна в первую очередь благодаря появлению на рынке дешевых, компактных датчиков изображения высокого разрешения, а также появлению дешевой элементной базы для цифровой обработки изображения: процессоров с высокой производительностью и большой памятью, дешевой КМОП-ОЗУ, flash-памяти для хранения больших объемов графической информации. Наличие на рынке данных компонентов позволило перейти от чисто исследовательских работ к выпуску массовых и доступных для широкого применения устройств. На рис. 1 показана структура реализации алгоритма распознавания лица человека.
Изображение с видеосенсора (микровидеокамеры) сначала преобразуется в цифровую форму, далее производится фильтрация артефактов изображения, выделение зоны лица, выравнивание контура лица, выделенного из кадра, построение графической модели лица для параметрической оценки деталей (размеров, положения и т. п.). Характерный набор параметров персоны затем сохраняется в базе данных и может быть использован для идентификации личности персоны. Таким образом, система распознавания состоит из двух компонентов: аппаратной части для захвата, обработки и сохранения изображения и отдельной программы, которая и обеспечивает необходимые процедуры для выделения и идентификации лиц в захваченном кадре изображения.
Писец 2.0
Это браузерный вариант имитатора рукописного текста. Вы его найдете, просто введя в любом поисковике запрос «писец». Можно конвертировать русский и английский текст.
Конвертер очень простой в использовании:
-
В левой части экрана введите печатный текст.
-
Нажмите кнопку «Перевести в рукопись».
-
В правой части экрана появится этот же текст в виде рукописи. Сохраните рукописный текст в формате PNG, кликнув правой кнопкой мыши и выбрав команду «Сохранить картинку как».
Плюсы:
-
Бесплатное использование.
-
Нет необходимости устанавливать программу.
-
Простой и понятный интерфейс.
Минусы:
-
Отсутствуют настройки – вы можете использовать только один почерк.
-
Невозможно создавать рукописи на тетрадных листах – вам доступен только белый фон.
-
Нельзя менять цвет ручки – доступен только стандартный синий цвет.
Редактируйте любые PDF-файлы легко и быстро
PDFelement для Windows существенно упрощает редактирование PDF. Меняйте водяные знаки, изображения, тексты, ссылки, колонтитулы, фоны, разметку страниц и многое другое!
Текст
Используйте интуитивно понятные режимы абзаца и отдельной строки для удобного редактирования текста. Меняйте шрифт, стиль и размер по мере необходимости.
Изображения
Работайте с изображениями без усилий, добавляя, поворачивая, распаковывая, обрезая, вставляя, заменяя, копируя и удаляя картинки.
Страницы
Преобразуйте документы с легкостью. Извлекайте, обрезайте, заменяйте, вставляйте и разделяйте страницы, настраивайте поля или добавляйте разметку страниц.
VisionLabs Luna
ÐÑÐ½Ð¾Ð²Ð½Ð°Ñ ÑÑаÑÑÑ: VisionLabs Luna
ÐлаÑÑоÑма ÑаÑÐ¿Ð¾Ð·Ð½Ð°Ð²Ð°Ð½Ð¸Ñ Ð»Ð¸Ñ VisionLabs LUNA — ÑлагманÑкий пÑодÑÐºÑ ÐºÐ¾Ð¼Ð¿Ð°Ð½Ð¸Ð¸ VisionLabs. LUNA позволÑÐµÑ Ð² Ñежиме ÑеалÑного вÑемени анализиÑоваÑÑ ÐºÐ¾Ð»Ð¾ÑÑалÑнÑе обÑÐµÐ¼Ñ ÑоÑо- и видеоданнÑÑ Ñ ÑелÑÑ Ð¾Ð¿ÑÐµÐ´ÐµÐ»ÐµÐ½Ð¸Ñ Ð² Ð½Ð¸Ñ Ð»Ð¸Ñ Ð»Ñдей и ÑÑÐ°Ð²Ð½ÐµÐ½Ð¸Ñ Ð¸Ñ Ñ Ð¼Ð½Ð¾Ð³Ð¾Ð¼Ð¸Ð»Ð»Ð¸Ð¾Ð½Ð½Ñми базами даннÑÑ. Ðа базе данной ÑеÑнологии Ñакже Ñоздан облаÑнÑй ÑеÑÐ²Ð¸Ñ FACE_IS, коÑоÑÑй Ð¼Ð¾Ð¶ÐµÑ ÑвÑзÑваÑÑ ÐºÐ»Ð¸ÐµÐ½Ñов Ñ Ð¿ÑедÑеÑÑвÑÑÑей иÑÑоÑией Ð¸Ñ Ð¿Ð¾ÐºÑпок и помогаÑÑ Ð²ÑÑÑÑаиваÑÑ Ð²Ð·Ð°Ð¸Ð¼Ð¾Ð´ÐµÐ¹ÑÑвие Ñ Ð±Ñендом. РеÑÐµÐ½Ð¸Ñ ÐºÐ¾Ð¼Ð¿Ð°Ð½Ð¸Ð¸ ÑвлÑÑÑÑÑ plugâ&âplay, по ÑмолÑÐ°Ð½Ð¸Ñ Ð¸Ð¼ÐµÑÑ Ð¸Ð½ÑегÑаÑÐ¸Ñ Ñ Ð±Ð¾Ð»ÑÑинÑÑвом баз даннÑÑ, CRM и BI-ÑиÑÑем, и не ÑÑебÑÑÑ Ð¾Ñ Ð¿Ð¾Ð»ÑзоваÑелей Ð·Ð°Ð¼ÐµÐ½Ñ Ð¾Ð±Ð¾ÑÑдованиÑ, Ñак как инÑегÑиÑÑÑÑÑÑ Ð² Ð¸Ñ ÑÑÑеÑÑвÑÑÑÑÑ IT- инÑÑаÑÑÑÑкÑÑÑÑ.
ÐÐ¾Ð¼Ð¿Ð°Ð½Ð¸Ñ Ð±Ñла оÑнована в 2012 Ð³Ð¾Ð´Ñ Ð¸ ÑвлÑеÑÑÑ ÑезиденÑом IT-клаÑÑеÑа «Сколково». ÐÐ¾Ð¼Ð¿Ð°Ð½Ð¸Ñ ÑпеÑиализиÑÑеÑÑÑ Ð½Ð° ÑеÑениÑÑ, позволÑÑÑÐ¸Ñ ÑаÑпознаваÑÑ Ð»Ð¸Ñа клиенÑов в ÑамÑÑ Ð±ÑÑÑÑоÑаÑÑÑÑÐ¸Ñ ÑегменÑÐ°Ñ ÑÑнка: банковÑкий ÑекÑÐ¾Ñ Ð¸ ÑиÑейл. Ð 2016 Ð³Ð¾Ð´Ñ ÐаÑÑаÑÑÑеÑÑкий ÑнивеÑÑиÑÐµÑ (СШÐ) вклÑÑил VisionLabs в ÑÑÐ¾Ð¹ÐºÑ Ð»ÑÑÑÐ¸Ñ Ð¼Ð¸ÑовÑÑ ÑиÑÑем в облаÑÑи ÑаÑÐ¿Ð¾Ð·Ð½Ð°Ð²Ð°Ð½Ð¸Ñ Ð»Ð¸Ñ Ð´Ð»Ñ ÐºÐ¾Ð¼Ð¼ÐµÑÑеÑÐºÐ¸Ñ Ñелей.
Классификация по ближайшему среднему значению
В классическом подходе распознавания образов, в котором неизвестный объект для классификации представляется в виде вектора элементарных признаков. Система распознавания на основе признаков может быть разработана различными способами. Эти векторы могут быть известны системе заранее в результате обучения или предсказаны в режиме реального времени на основе каких-либо моделей.
Простой алгоритм классификации заключается в группировке эталонных данных класса с использованием вектора математического ожидания класса (среднего значения).
где x(i,j)– j-й эталонный признак класса i, n_j– количество эталонных векторов класса i.
Тогда неизвестный объект будет относиться к классу i, если он существенно ближе к вектору математического ожидания класса i, чем к векторам математических ожиданий других классов. Этот метод подходит для задач, в которых точки каждого класса располагаются компактно и далеко от точек других классов.
Трудности возникнут, если классы будут иметь несколько более сложную структуру, например, как на рисунке. В данном случае класс 2 разделен на два непересекающихся участка, которые плохо описываются одним средним значением. Также класс 3 слишком вытянут, образцы 3-го класса с большими значениями координат x_2 ближе к среднему значению 1-го класса, нежели 3-го.
Описанная проблема в некоторых случаях может быть решена изменением расчета расстояния.
Будем учитывать характеристику «разброса» значений класса – σ_i, вдоль каждого координатного направления i. Среднеквадратичное отклонение равно квадратному корню из дисперсии. Шкалированное евклидово расстояние между вектором x и вектором математического ожидания x_c равно
Эта формула расстояния уменьшит количество ошибок классификации, но на деле большинство задач не удается представить таким простым классом.
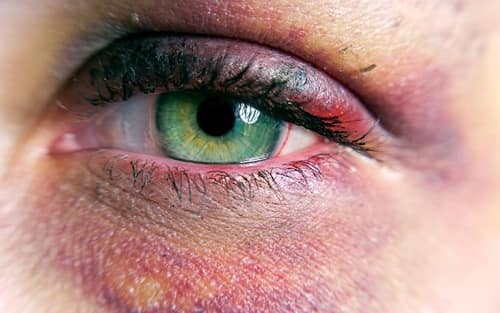
Синяки на лице – отчего и почему?
Синяки или, как их называют врачи, гематомы – это ограниченное скопление крови при разрыве мелких кровеносных сосудов — капилляров и образованием полости, в которой и скапливается вытекающая из поврежденных сосудов кровь.
Чаще всего это происходит в результате резкого и сильного механического воздействия и ушиба мягких тканей лица. Основными симптомами является боль, наличие ограниченной припухлости и появление покраснения кожи. Со временем постепенно цвет гематомы изменяется от лилово-красного до багрово-синюшного и желто-зеленого.
Если подобная травма не сопровождается нарушением кожных покровов, то большинство не обращаются в лечебное учреждение и стараются самостоятельно и быстрее избавиться от этого косметического дефекта. С одной стороны, это и правильно, поскольку небольшие ушибы мягких тканей лица опасности для здоровья не представляют.
Но если, кровоподтек обширный или он появился без всякой причины, то это повод как можно быстрее обратиться за медицинской помощью. В этой ситуации необходимо дополнительное обследование, при котором может выявиться более серьезная и угрожающая жизни патология.По степени тяжести гематомы выглядят по-разному:
- Легкая степень. Проявляется в первые сутки после травмы, болезненность при пальпации незначительная, отмечается небольшая припухлость красного цвета.
- Средняя степень тяжести. Кровоподтек появляется уже через несколько часов после травмы. В процесс затронуты и нижележащие ткани и мышцы, отчего при надавливании чувствуется боль и даже невооруженным глазом видна припухлость.
- Тяжелая степень тяжести. Проявляется сразу же после травмы в течение часа. Опухоль на месте гематомы более выражена и очень болезненна при надавливании. Именно при таких гематомах надо обязательно показаться врачу.
Цвет синяка меняется постепенно. Через 2-3 дня красный оттенок меняется на багровый, а затем на фиолетовый. Затем цвет постепенно меняется с темного на желтый, начиная с краев кровоподтека и доходит до центра. Здесь уже болезненность места ушиба становится менее выраженной.
Примерно через неделю цвет гематомы приобретает зеленоватый оттенок. И в это же время кровоподтек как бы спускается ниже, но этого бояться не стоит, так как здесь срабатывает сила тяжести и полость с остатками спекшейся крови опускается книзу. В этой стадии боль и припухлость исчезают, а кожа постепенно приобретает естественный цвет.
На все, если не воспользоваться средствами для быстрого удаления синяка, уйдет примерно 1,5-2 недели. Для многих — это слишком долго.
Как это обычно делают?
На практике учитывать всё это редко когда бывает нужно. Например, для маленькой рукописной распечатки на открытке или приглашении используют обычный рукописный шрифт OpenType. Впрочем, в определённых условиях это может подойти и для конспекта. В сети можно найти инструкции, как создать индивидуальный шрифт самостоятельно и печатать им из MS Word, а для англоязычных пользователей существуют целые генераторы рукописных шрифтов.
Но при таком способе страдает правдоподобность: символы будут абсолютно одинаковыми, строки безупречно ровными. Не будет никакой случайности, вырвиглазности и хаоса, которые по моему опыту характерны для подавляющего большинства конспектов, и даже для аккуратного конспекта такая безупречность неестественна.
#1. PDFelement Pro
PDFelement Pro- идеальный инструмент для OCR распознавания PDF-файлов. Он может автоматически распознавать отсканированные файлы PDF и делать их редактируемыми с помощью встроенных инструментов редактирования. Кроме этого, он поддерживает несколько языков OCR. Вы можете легко редактировать ваши PDF-тексты, изображения, ссылки и другие элементы. Также у вас есть возможность конвертировать PDF-файлы в другие форматы.
Основные функции данной PDF OCR программы:
- Расширенная функция OCR позволяет легко конвертировать и редактировать отсканированные PDF-файлы.
- Редактирование текстов PDF, изображений и ссылок – такое же простое, как и внесение изменений в Word.
- С легкостью добавляйте подпись, пароль, водяные знаки, знаки, нарисованные от руки в PDF-файлы.
- Размещайте комментарии и примечание, где вам необходимо.
- Вы также можете просто создавать PDF из множества других форматов.
- Кроме этого, у вас есть возможность конвертировать PDF в такие форматы, как Excel, MS Word и другие.
#2. OCR Desktop
Это OCR приложение для настольного компьютера включает в себя искусственный интеллект и нейронные сети для улучшения качества работы. Конвертер курсивного письма PDF в текст обучали более, чем четырём миллионам вариантов шрифтов, так что вы можете быть уверены, преобразованный текст будет точным насколько это вообще возможно. Он также владеет новейшей технологией OCR для решения любой задачи в распознавании почерка. А что, если мы добавим, что приложение является бесплатным для личного использования? Тем не менее, в нем есть реклама, но если вы хотите избавиться от нее, то необходимо получить зарегистрированную версию.
#3. SimpleOCR
SimpleOCR – одна из самых популярных бесплатных программ OCR доступных в сети. Она довольно проста, но в ее арсенале есть все основные функции сканирования и конвертации, которые важны при работе с OCR распознаванием рукописных текстов. Однако если вы хотите расширенные возможности, то тогда вам необходимо воспользоваться платной версией.
#4. TopOCR
Создатели TopOCR говорят, что они создали наиболее мощную систему распознавания, на основе нейронной сети, которая доступна на рынке, а также обещают пользователям лучшие результаты OCR распознавания данных, сделанных с помощью цифровой камеры. Поэтому, если у вас есть письмо, которое вы хотите оцифровать, сфотографируйте его и позвольте TopOCR выполнить свою работу. К сожалению, приложение было бесплатным некоторое время назад, но сегодня вам придется купить его, чтобы использовать. Но разработчики действительно используют сложные алгоритмы обработки изображений, чтобы гарантировать отличный результат!
Методы распознавания образов
В целом, можно выделить следующие методы распознавания образов:
- Метод перебора. В этом случае производится сравнение с базой данных, где для каждого вида объектов представлены всевозможные модификации отображения. Например, для оптического распознавания образов можно применить метод перебора вида объекта под различными углами, масштабами, смещениями, деформациями и т. д. Для букв нужно перебирать шрифт, свойства шрифта и т. д. В случае распознавания звуковых образов, соответственно, происходит сравнение с некоторыми известными шаблонами (например, слово, произнесенное несколькими людьми).
- Второй подход — производится более глубокий анализ характеристик образа. В случае оптического распознавания это может быть определение различных геометрических характеристик. Звуковой образец в этом случае подвергается частотному, амплитудному анализу и т. д.
- Следующий метод — использование искусственных нейронных сетей (ИНС). Этот метод требует либо большого количества примеров задачи распознавания при обучении, либо специальной структуры нейронной сети, учитывающей специфику данной задачи. Тем не менее, его отличает более высокая эффективность и производительность. .
- Экспертный метод, основанный на непрерывном обучении экспертной системы в процессе эксплатации.
Персептрон как метод распознавания образов
Ф. Розенблатт, вводя понятие о модели мозга, задача которой состоит в том, чтобы показать, как в некоторой физической системе, структура и функциональные свойства которой известны, могут возникать психологические явления — описал простейшие эксперименты по различению. Данные эксперименты целиком относятся к методам распознавания образов, но отличаются тем, что алгоритм решения не детерминированный. Простейший эксперимент, на основе которого можно получить психологически значимую информацию о некоторой системе, сводится к тому, что модели предъявляются два различных стимула и требуется, чтобы она реагировала на них различным образом. Целью такого эксперимента может быть исследование возможности их спонтанного различения системой при отсутствии вмешательства со стороны экспериментатора, или, наоборот, изучение принудительного различения, при котором экспериментатор стремится обучить систему проводить требуемую классификацию. В опыте с обучением персептрону обычно предъявляется некоторая последовательность образов, в которую входят представители каждого из классов, подлежащих различению. В соответствии с некоторым правилом модификации памяти правильный выбор реакции подкрепляется. Затем персептрону предъявляется контрольный стимул и определяется вероятность получения правильной реакции для стимулов данного класса. В зависимости от того, совпадает или не совпадает выбранный контрольный стимул с одним из образов, которые использовались в обучающей последовательности, получают различные результаты: 1. Если контрольный стимул не совпадает ни с одним из обучающих стимулов, то эксперимент связан не только с чистым различением, но включает в себя и элементы обобщения. 2. Если контрольный стимул возбуждает некоторый набор сенсорных элементов, совершенно отличных от тех элементов, которые активизировались при воздействии ранее предъявленных стимулов того же класса, то эксперимент является исследованием чистого обобщения. Персептроны не обладают способностью к чистому обобщению, но они вполне удовлетворительно функционируют в экспериментах по различению, особенно если контрольный стимул достаточно близко совпадает с одним из образов, относительно которых персептрон уже накопил определенный опыт.